# Start the Master to output the Master URL
$ ./sbin/start-master.sh
# Start Worker(s) with the Master URL
$ ./sbin/start-slave.sh spark://<master-spark-URL>:7077
# Launch Spark Application on cluster specifying the Master URL
$ ./bin/spark-submit \
--master spark://<spark-master-URL>:7077 \
<additional configuration>Apache Hadoop Yarn
Spark
What is Apache Spark
Spark is an open-source, in-memory application framework for distributed data processing and iterative analysis on massive data volumes.
- First, Spark is entirely open source. Spark is available under the Apache Foundation hence the name Apache Spark.
- Spark is “in-memory,” which means that all operations happen within the memory or RAM.
- Distributed data processing uses Spark.
- Spark scales very well with data, which is ideal for massive datasets.
- Spark is primarily written in Scala, a general-purpose programming language that supports both object-oriented and functional programming.
- Spark runs on Java virtual machines.
- Spark checks the boxes for all the benefits of distributed computing.
- Spark supports a computing framework for large-scale data processing and analysis.
- Spark also provides parallel distributed data processing capabilities, scalability, and fault-tolerance on commodity hardware.
- Spark provides in-memory processing and creates a comprehensive, unified framework to manage big data processing.
- Spark enables programming flexibility with easy-to-use Python, Scala, and Java APIs.
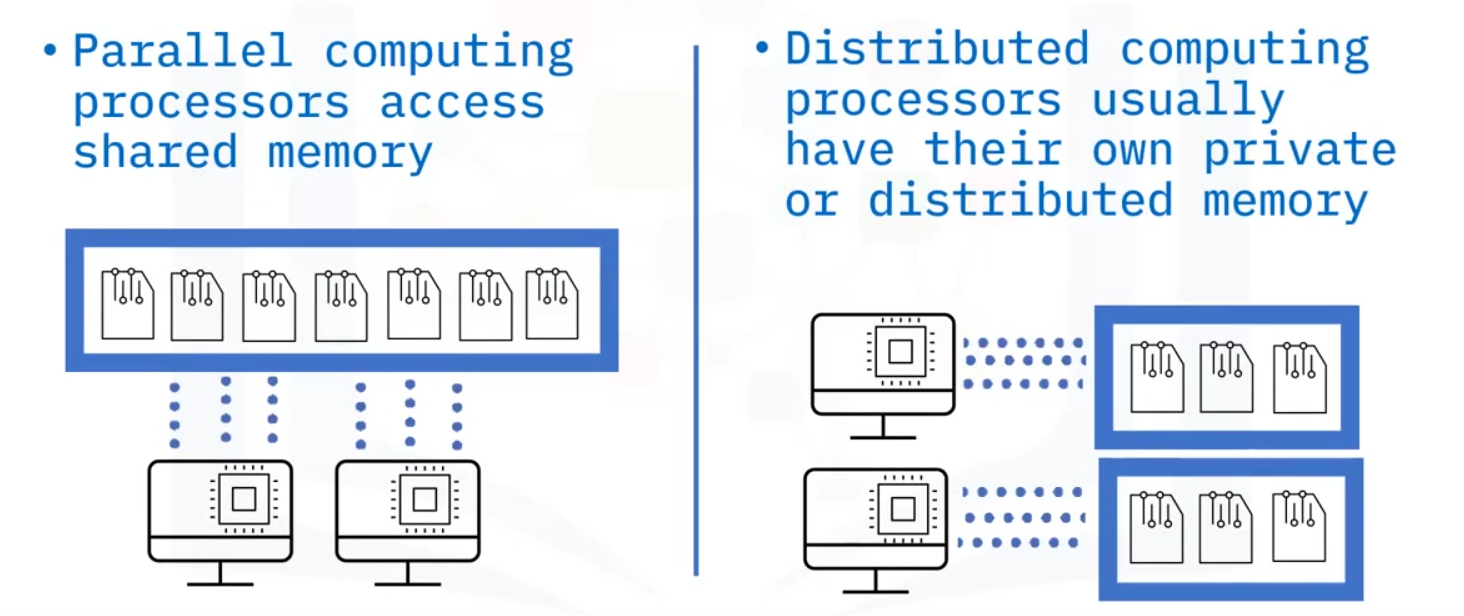
Distributed computing
As the name suggests, is a group of computers or processors working together behind the scenes.
- Distributed computing and parallel computing access memory differently.
- Typically, parallel computing shares all the memory, while in distributed computing, each processor accesses its own memory.
Benefits
- Distributed computing offers scalability and modular growth.
- Distributed systems are inherently scalable as they work across multiple machines and scale horizontally. A user can add additional machines to handle the increasing workload instead of repeatedly updating a single system, with virtually no cap for scalability.
- Distributed systems require both fault tolerance and redundancy as they use independent nodes that could fail.
- Distributed computing offers more than fault tolerance.
- Distributed computing provides redundancy that enables business continuity. For example, a business running a cluster of eight machines can continue to function whether a single machine or multiple machines go offline.
Spark vs MapReduce
Apache Spark solves the problems encountered with MapReduce by keeping a substantial portion of the data required in memory, avoiding expensive and time-consuming disk I/O.

A traditional MapReduce job creates iterations that require reads and writes to disk or HDFS.
- These reads and writes are usually time-consuming and expensive.

Apache Spark solves the read/write problems encountered with MapReduce by keeping much of the data required in-memory and avoiding expensive disk I/O, thus reducing the overall time by orders of magnitude.
Spark & Big Data
Spark provides big data solutions for both data engineering problems and data science challenges.
Data Engineering
Data engineers use Spark tools, including the core Spark engine, clusters and executors and their management, SparkSQL and DataFrames.
Machine Learning
Additionally, Spark also supports Data Science and Machine learning through libraries such as SparkML and Streaming.
Functional Programming
Functional Programming, or FP, is a style of programming that follows the mathematical function format.
- Think of an algebra class with f (x).
- The notation is declarative in nature as opposed to being imperative.
- By declarative, we mean that the emphasis of the code or program is on the “what” of the solution as opposed to the “how to” of the solution.
- Declarative syntax abstracts out the implementation details and only emphasizes on the final output, restated, “the what.”
- Use expressions in functional programming, like the expression f of x as mentioned earlier.
Functional programming was implemented in LISt Processing Language, known as LISP, which was the first functional programming language, starting in the 1950s. But today there are many functional programming language options including Scala, Python, R, and Java.
Here is a simple example of a functional program that increments a number by one. We define the function f(x) = x +1. We can then apply this function to a list of size four as shown in the figure, and the program increments every element in the list by one.
Parallelization
Parallelization is one of the main benefits of Functional Programming. All you need to do is to run more than one instance of the task in parallel. By applying implicit parallelization functional programming capabilities, you can scale the algorithm to any size by adding more compute and resources without modifying the program or code.

Functional programming applies a mathematical concept called lambda calculus.
- To keep the explanation simple, lambda calculus basically says that every computation can be expressed as an anonymous function which is applied to a data set.
- Lambda functions or operators are anonymous functions used to write functional programming code.
- Note how both codes are similar in flow, and abstract out the result directly, a hallmark of the declarative paradigm of programming.
RDD Resilient Distributed Datasets
A resilient distributed data set, also known as an RDD, is Spark’s primary data abstraction.
A resilient distributed data set, is a collection of fault tolerant elements partitioned across the cluster’s nodes capable of receiving parallel operations. Additionally, resilient distributed databases are immutable, meaning that these databases cannot be changed once created.
- You can create an RDD using an external or local Hadoop-supported file, from a collection, or from another RDD. RDDs are immutable and always recoverable, providing resilience in Apache Spark. RDDs can persist or cache datasets in memory across operations, which speeds up iterative operations in Spark.
- Every spark application consists of a driver program that runs the user’s main functions and runs multiple parallel operations on a cluster.
RDD’s Supported Files
RDD’s supported File Types:
- Text
- Sequence files
- Avro
- Parquet
- Hadoop input format file types.
RDD’s supported File Formats:
- Local
- Cassandra
- HBase
- HDFS
- Amazon S3
- Other file formats in addition to an abundance of relational and no SQL databases.
Parallel Programming
Parallel programming, like distributed programming, is the simultaneous use of multiple compute resources to solve a computational task. Parallel programming parses tasks into discrete parts that are solved concurrently using multiple processors.
The processors access a shared pool of memory, which has in place control and coordination mechanisms.
Resilience
RDD’s provide resilience in Spark through immutability and caching.
- First RDDs are always recoverable as the data is immutable.
- Another essential Spark capability is the persisting or caching of a data set in memory across operations.
- The cache is fault tolerant and always recoverable. as RDDs are immutable and the Hadoop data sources are also fault tolerant.
Persistence
In RDD, each node stores the partitions that the node computed in memory and reuses the same partition in other actions on that data set or the subsequent datasets derived from the first RDD.
- Persistence allows future actions to be much faster, often by more than 10 times.
- Persisting or caching is used as a key tool for iterative algorithms and fast interactive use.
Architecture
Apache Spark architecture consists of three main components.
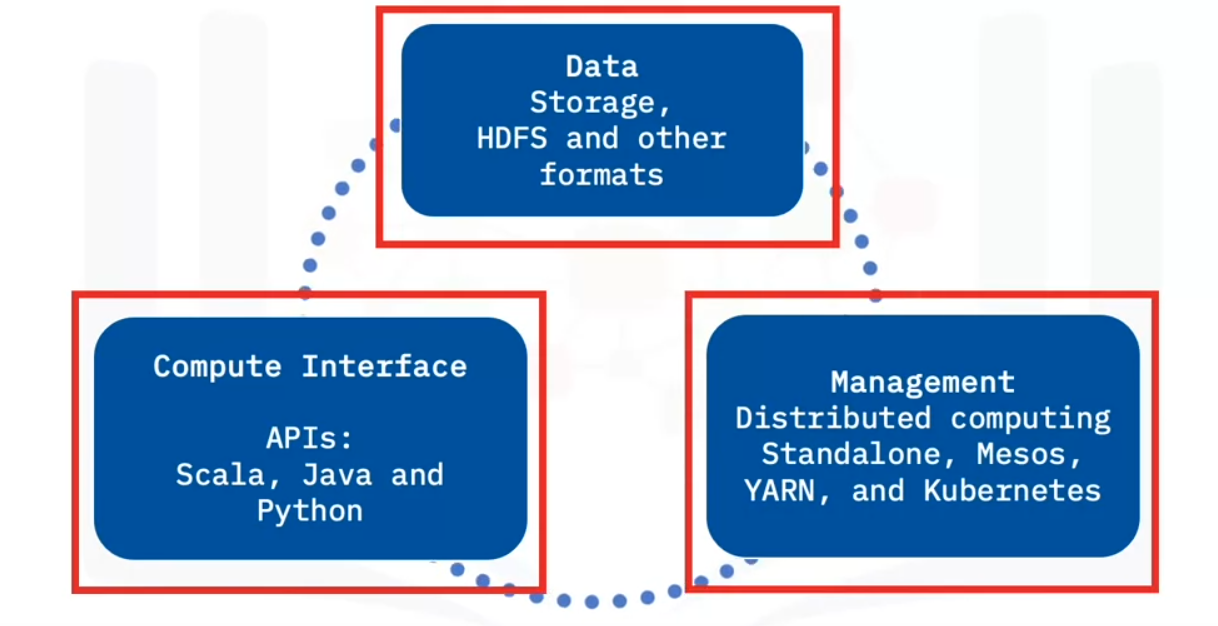
Data Storage
- Datasets load from data storage into memory
- Any Hadoop compatible data source is acceptable.
Compute Interface
- High-level programming APIs comprise the second component.
- Spark has APIs in Scala, Python, and Java.
Cluster Management
- The final component is the cluster management framework, which handles the distributed computing aspects of Spark.
- Spark’s cluster management framework can exist as a stand-alone server, Mesos or Yet Another Resource Network, or YARN.
- A cluster management framework is essential for scaling big data.
Spark Core
What is often referred to as “Spark” is the base engine formally called the “Spark Core.” The fault-tolerant Spark Core is the base engine for large-scale parallel and distributed data processing.
- Spark Core manages memory and task scheduling.
- Spark Core also contains the APIs used to define RDDs and other datatypes.
- Spark Core also parallelizes a distributed collection of elements across the cluster.
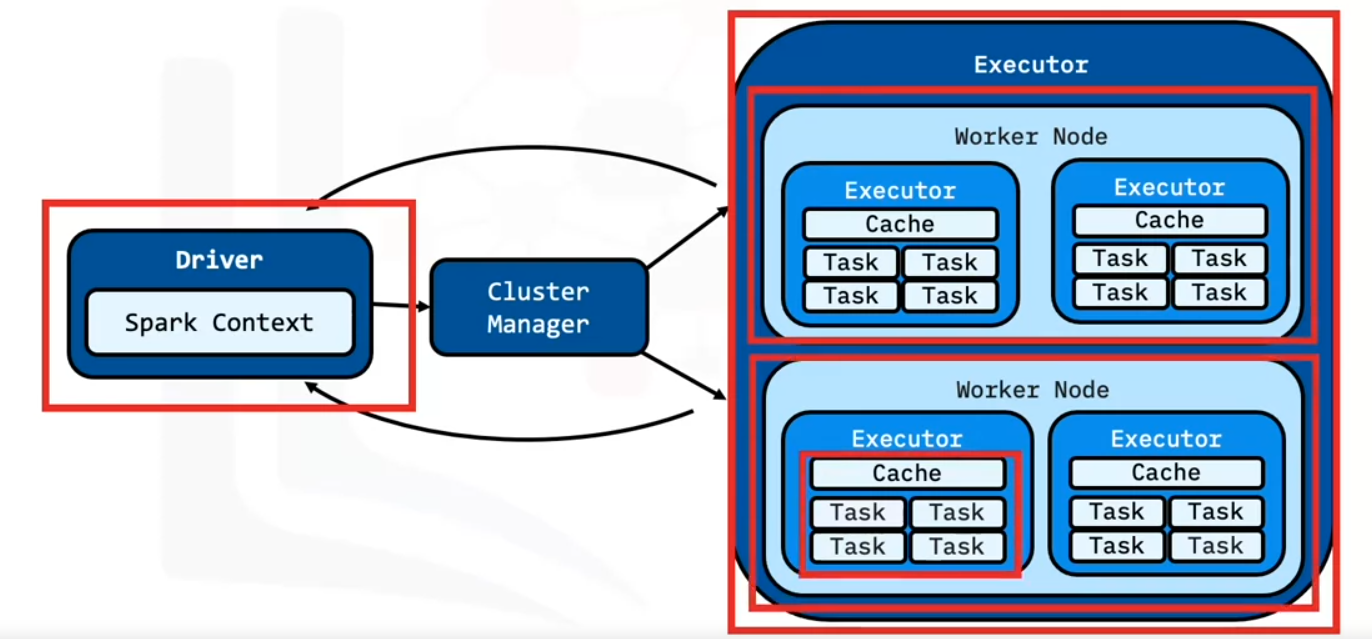
To understand how Spark scales with big data, let’s review the Spark Application Architecture.
- The Spark Application consists of the driver program and the executor program.
- Executor programs run on worker nodes.
- Spark can start additional executor processes on a worker if there is enough memory and cores available.
- Similarly, executors can also take multiple cores for multithreaded calculations.
- Spark distributes RDDs among executors.
- Communication occurs among the driver and the executors.
- The driver contains the Spark jobs that the application needs to run and splits the jobs into tasks submitted to the executors.
- The driver receives the task results when the executors complete the tasks.
If Apache Spark were a large organization or company, the driver core would be the executive management of that company that makes decisions about allocating work, obtaining capital, and more.
- The junior employees are the executors who do the jobs assigned to them with the resources provided.
- The worker nodes correspond to the physical office space that the employees occupy.
- You can add additional worker nodes to scale big data processing incrementally.
Spark Processes
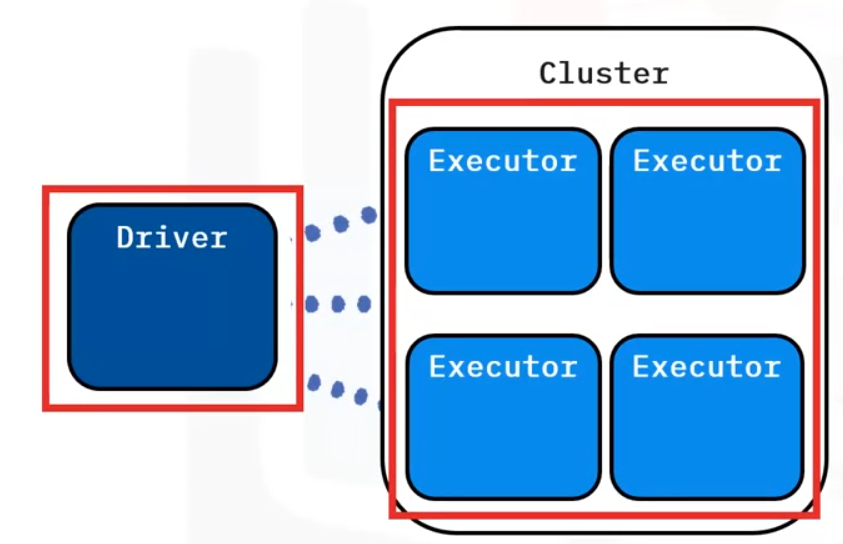
A spark application has two main processes:
Driver Program
A single process that creates work for the cluster. The driver process can be run on a cluster node or another machine as a client to the cluster. The driver runs the application’s user code, creates work and sends it to the cluster.
The driver program can be run in either client or cluster mode.
- In client mode the application submitter (such as a user machine terminal) launches the driver outside the cluster.
- In cluster mode, the driver program is sent to and run on an available Worker node inside the cluster.
The driver must be able to communicate with the cluster while it is running, whether it is in client or cluster mode.
Executors
Multiple processed throughout the cluster that do the work in parallel. An executor is a process running multiple threads to perform work concurrently for the cluster. Executors work independently. There can be many throughout a cluster and one or more per node, depending on configuration.
- A Spark Executor utilizes a set portion of local resources as memory and compute cores, running one task per available core. Each executor manages its data caching as dictated by the driver.
- In general, increasing executors and available cores increases the cluster’s parallelism.
Spark Context
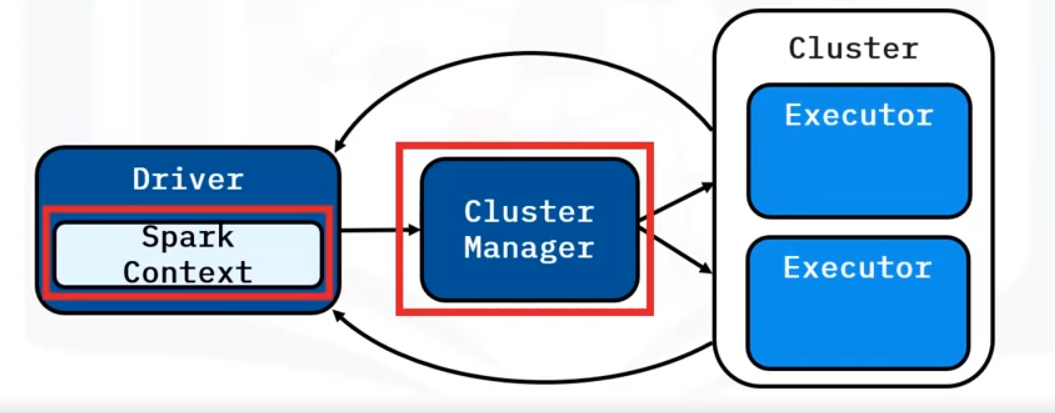
The Spark Context starts when the application launches and must be created in the driver before DataFrames or RDDs. Any DataFrames or RDDs created under the context are tied to it and the context must remain active for the life of them.
The driver program creates work from the user code called “Jobs” (or computations that can be performed in parallel).
The Spark Context in the driver divides the jobs into tasks to be executed on the cluster.
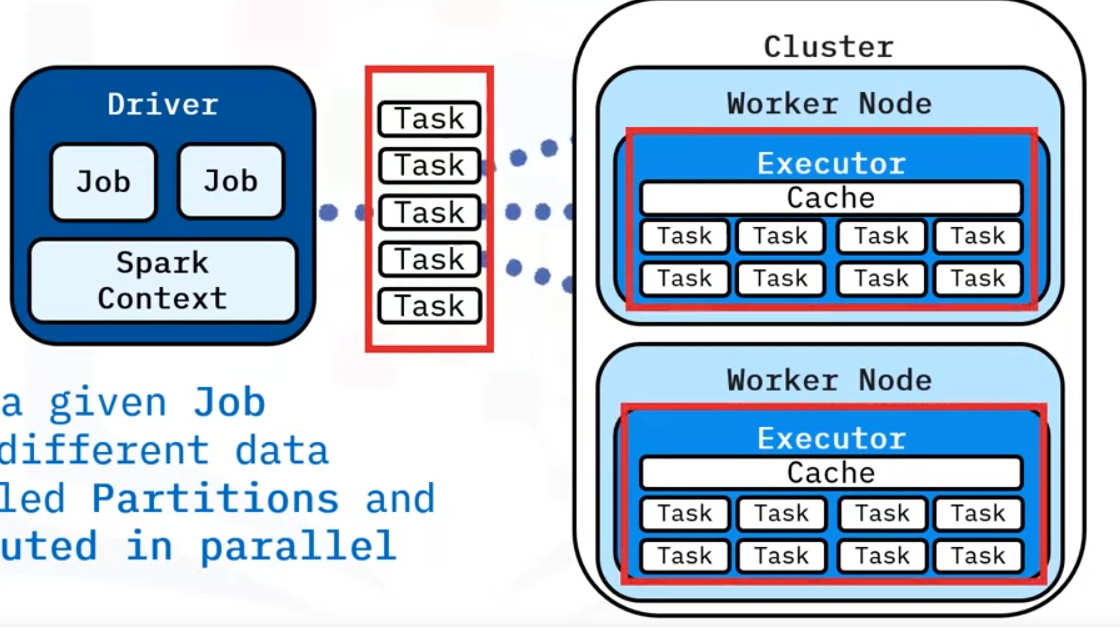
Tasks
- Tasks from a given job operate on different data subsets, called Partitions.
- This means tasks can run in parallel in the Executors.
- A Spark Worker is a cluster node that performs work.
- Tasks run in separate threads until all cores are used.
- When a task finishes, the executor puts the results in a new RDD partition or transfers them back to the driver.
Ideally, limit utilized cores to total cores available per node. For instance, an 8-core node could have 1 executor process using 8 cores.
Stage & Shuffle
A “stage” in a Spark job represents a set of tasks an executor can complete on the current data partition.
- When a task requires other data partitions, Spark must perform a “shuffle.”
- A shuffle marks the boundary between stages. Subsequent tasks in later stages must wait for that stage to be completed before beginning execution, creating a dependency from one stage to the next.
- Shuffles are costly as they require data serialization, disk and network I/O. This is because they enable tasks to “pass over” other dataset partitions outside the current partition.
- An example would be a “groupby” with a given key that requires scanning each partition to find matching records.
- When Spark performs a shuffle, it redistributes the dataset across the cluster.
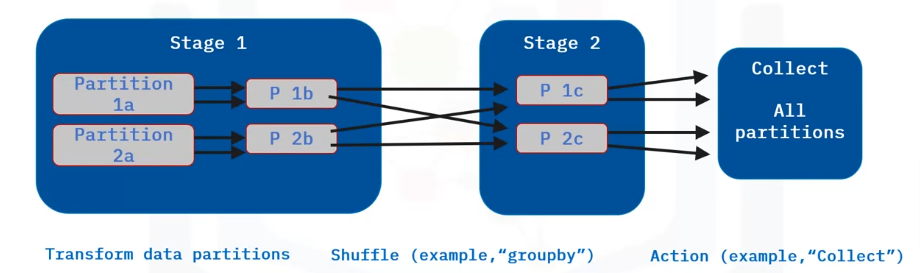
This example shows two stages separated by a shuffle.
- In Stage 1, a transformation (such as a map) is applied on dataset “a” which has 2 partitions (“1a” and “2b”). This creates data set “b”.
- The next operation requires a shuffle (such as a “groupby”).
- Key values could exist in any other partition, so to group keys of equal value together, tasks must scan each partition to pick out the matching records.
- Transformation results are placed in Stage 2. Here results have the same number of partitions, but this depends on the operation.
- Final results are sent to the driver program as an action, such as collect.
NOTE: It is not advised to perform a collection to the driver on a large data set as it could easily use up the driver process memory. If the data set is large, apply a reduction before collection.
Cluster Managers

Spark supports the following cluster managers:
Standalone
Spark Standalone - comes with Spark, and is best for setting up a simple cluster, is often the fastest way to get a cluster up and running applications. Designed for Spark only not for general purpose
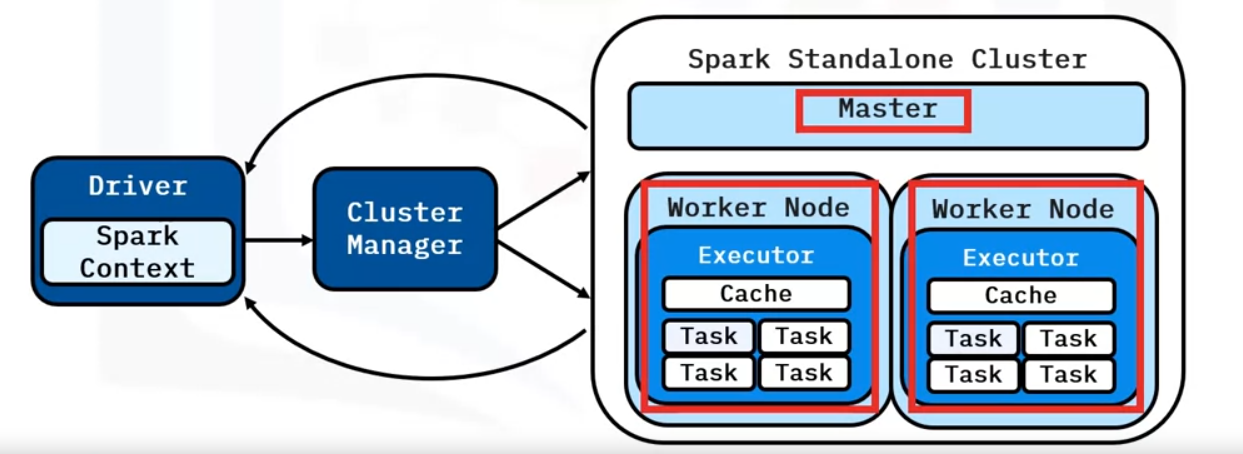
It is comprised of
- Workers - run an Executor porcess to receive tasks
- Master - connects and adds workers to the cluster
Setup
Apache Hadoop YARN - from the Haddop project
- Is general purpose
- Supports many other big data ecosytem frameworks
- Requires its own configuration and setup
- Has dependencies, making it more complex to deploy than Spark Standalone
- Spark will automatically connect with YARN using Hadoop configuration once we run the command below
Setup
# Run Spark on existing YARN cluster
$ ./bin/spark-submit \
--master YARN \
<additional configuration>Apache Mesos
Apache Mesos - is a general purpose cluster manager with additional benefits such as
- making partitioning
- Scalable between many Spark instances
- Dynamic between Spark and other big data frameworks
Kubernetes
Kubernetes - an open source system running containerized applications which makes it easier to
- Automate deployment
- Simplify dependency management
- Scale the cluster
Kubernetes is a container orchestrator which allows to schedule millions of “docker” containers on huge compute clusters containing thousands of compute nodes. Originally invented and open-sourced by Google, Kubernetes became the de-facto standard for cloud-native application development and deployment inside and outside IBM. With RedHat OpenShift, IBM is the leader in hybrid cloud Kubernetes and within the top three companies contributing to Kubernetes’ open source code base.
Setup
To launch a Spark Application on k8s
$ ./bin/spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
<additional configuration>Local Mode
Local mode runs a Spark application as a single process locally on the machine.
- Executors are run as separate threads in the main process that calls ‘spark-submit’.
- Local mode does not connect to any cluster or require configuration outside a basic Spark installation.
- Local mode can be run on a laptop.
- That’s useful for testing or debugging a Spark application, for example, testing a small data subset to verify correctness before running the application on a cluster.
- However, being constrained by a single process means local mode is not designed for optimal performance.
Setup
- To run in local mode, use the ‘–master’ option with the keyword ‘local’ followed by a number to indicate how many cores the Spark application can use for the executor.
- To use all available cores, replace the number with an asterisk wildcard.
- Keep in mind not all configuration for a cluster will be valid in local mode.
# Launch Spark in local mode with 8 cores
$ ./bin/spark-submit \
--master local[8] \
<additional configuration>Deployment Types
Local Machine
Description: Running Spark on your local machine is the most straightforward way to start with Spark. It’s suitable for development, small-scale data processing, and testing Spark applications.
When to Use:
- Development and Testing: You can employ a local machine to develop and test Spark applications before you deploy them to a larger cluster.
- Small Data Sets: You can use a local machine for small data sets that fit in your computer’s memory.
- Learning and Prototyping: Local machines are ideal for learning Spark or prototyping Spark applications.
On-Premises Cluster
Description: Deploying Spark on an on-premises cluster involves setting up a cluster of physical servers within your own data center. This helps you gain more control over hardware and network configurations.
When to Use:
- Data Security and Compliance: You can use the on-premises cluster approach when on-premises data processing becomes mandatory according to the data security and compliance requirements.
- Resource Control: With the on-premises cluster approach, you can control over hardware resources completely, making it suitable for specific hardware requirements.
- Long-term Stability: You can use the on-premises cluster approach if your organization is committed to on-premises infrastructure.
Cloud
Description: Deploying Apache Spark on the cloud provides you with scalable and flexible solutions for data processing. In the cloud, you can manage your own Spark cluster or leverage managed services offered by public cloud providers.
Managed Services Providers:
1. IBM Cloud
Description: IBM Cloud offers Spark support through IBM Cloud Pak for Data. This provides a unified data and AI platform with Spark capabilities.
When to Use:
- IBM Ecosystem: IBM Cloud is a seamless choice if your organization uses IBM technologies and services.
- Data and AI Integration: IBM Cloud can be utilized by organizations wanting to integrate Spark with AI and machine learning workflows.
- Hybrid Cloud: IBM Cloud is suitable for hybrid cloud deployments, helping you to connect on-premises and cloud-based resources.
2. Azure HDInsight
Description: Azure HDInsight is a cloud-based big data platform by Microsoft that supports Spark and other big data tools. It offers a managed environment and allows integration into Azure services.
When to Use:
- Microsoft Ecosystem: If your organization relies on Microsoft technologies, HDInsight provides you with a natural fit for Spark integration.
- Managed Services: Azure HDInsight plays a part when you want a fully managed Spark cluster without worrying about infrastructure management.
- Hybrid Deployments: Azure HDInsight is ideal for hybrid deployments where some data resides on-premises and some in Azure.
3. AWS EMR (Elastic MapReduce)
Description: Amazon EMR is a cloud-based big data platform that makes it easy for Spark to run on AWS. EMR offers scalability, easy management, and integration with other AWS services.
When to Use:
- Scalability: EMR allows you to process large data sets and scale resources up or down based on demand.
- AWS Integration: If your data ecosystem is already on AWS, EMR can integrate with other AWS services seamlessly.
- Cost Efficient: EMR allows you to pay only for the resources you use, making it cost-effective for variable workloads.
4. Databricks
Description: Databricks is a unified analytics platform that offers you a fully managed Spark environment. It simplifies Spark deployment, management, and collaboration among data teams.
When to Use:
- Collaboration: When multiple data teams need to work together on Spark projects, Databricks provides you with collaboration features.
- Managed Environment: Databricks takes care of infrastructure, making it easier for you to focus on data processing and analysis.
- Advanced Analytics: Databricks is suitable for advanced analytics and machine learning projects due to integrated libraries and notebooks.
SparkSQL & Dataframes
SparkSQL
- SparkSQL is a Spark module for structured data processing.
- You can interact with Spark SQL using SQL queries and the DataFrame API.
- Spark SQL supports Java, Scala, Python, and R APIs.
- Spark SQL uses the same execution engine to compute the result independently of which API or language you are using for the computation.
results = spark.sql(
"SELECT * FROM people")
names = results.map(lambda p:p.name)Above is an example of a Spark SQL query using Python.
- The query select ALL rows from people statement is the SQL query run using Spark SQL.
- The entity “people” was registered as a table view before this command.
- Unlike the basic Spark RDD API, Spark SQL includes a cost-based optimizer, columnar storage, and code generation to perform optimizations that provide Spark with additional information about the structure of both the data and the computation in process.
Dataframe
A DataFrame is a collection of data organized into named columns.
- DataFrames are conceptually equivalent to a table in a relational database and similar to a data frame in R/Python, but with richer optimizations.
- DataFrames are built on top of the Spark SQL RDD API.
- DataFrames use RDDs to perform relational queries.
df = spark.read.json("people.json")
df.show()
df.printSchema()
# Register the DataFrame as SQL temporary view
df.createTempView("people")
Above is a simple code snippet in Python to read from a JSON file and create a simple DataFrame.
- The last step of registering the DataFrame runs SQL queries on this data using Spark SQL.
- Here you see the input data file in JSON format and the resulting DataFrame.
Benefits
- DataFrames are highly scalable—from a few kilobytes on a single laptop to petabytes on a large cluster of machines.
- DataFrames support a wide array of data formats and storage systems.
- DataFrames provide optimization and code generation through a Catalyst optimizer.
- DataFrames are developer-friendly, offering integration with most big data tooling via Spark and APIs for Python, Java, Scala, and R.
# SparkSQL
spark.sql("SELECT name FROM people").show()
# DataFrame Python API
df.select("name").show()
# OR
df.select(df["name"]).show()
# OUTPUT
These code snippets show how to run the same SQL query and the result of those queries using Spark SQL.
- All three queries show here achieve the same result of showing the names column from our DataFrame.
- The first query is a more traditional SQL query, while
- The other two code examples use the DataFrame Python API to perform the same task.
Another comparison:
# SparkSQL
spark.sql("
SELECT age, name
FROM people
WHERE age > 21
")
# Or DataFrame Python API
df.filter(df["age"]>21).show()
#OUTPUT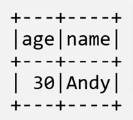
Glossary 1
| Term | Definition |
|---|---|
| Amazon Simple Storage Service (Amazon S3) | An object store interface protocol that Amazon invented. It is a Hadoop component that understands the S3 protocol. S3 provides an interface for Hadoop services, such as IBM Db2 Big SQL, to consume S3-hosted data. |
| Apache Spark | An in-memory and open-source application framework for distributed data processing and iterative analysis of enormous data volumes. |
| Application programming interface (API) | Set of well-defined rules that help applications communicate with each other. It functions as an intermediary layer for processing data transfer between systems, allowing companies to open their application data and functionality to business partners, third-party developers, and other internal departments. |
| Big data | Data sets whose type or size supersedes the ability of traditional relational databases to manage, capture, and process the data with low latency. Big data characteristics include high volume, velocity, and variety. |
| Classification algorithms | A type of machine learning algorithm that helps computers learn how to categorize things into different groups based on patterns they find in data. |
| Cluster management framework | It handles the distributed computing aspects of Spark. It can exist as a stand-alone server, Apache Mesos, or Yet Another Resource Network (YARN). A cluster management framework is essential for scaling big data. |
| Commodity hardware | Consists of low-cost workstations or desktop computers that are IBM-compatible and run multiple operating systems such as Microsoft Windows, Linux, and DOS without additional adaptations or software. |
| Compute interface | A shared boundary in computing against which two or more different computer system components exchange information. |
| Data engineering | A prominent practice that entails designing and building systems for collecting, storing, and analyzing data at scale. It is a discipline with applications in different industries. Data engineers use Spark tools, including the core Spark engine, clusters, executors and their management, Spark SQL, and DataFrames. |
| Data science | Discipline that combines math and statistics, specialized programming, advanced analytics, artificial intelligence (AI), and machine learning with specific subject matter expertise to unveil actionable insights hidden in the organization’s data. These insights can be used in decision-making and strategic planning. |
| DataFrames | Data collection categorically organized into named columns. DataFrames are conceptually equivalent to a table in a relational database and similar to a dataframe in R or Python, but with greater optimizations. They are built on top of the Spark SQL RDD API. They use RDDs to perform relational queries. Also, they are highly scalable and support many data formats and storage systems. They are developer-friendly, offering integration with most big data tools via Spark and APIs for Python, Java, Scala, and R. |
| Declarative programming | A programming paradigm that a programmer uses to define the program’s accomplishment without defining how it needs to be implemented. The approach primarily focuses on what needs to be achieved, rather than advocating how to achieve it. |
| Distributed computing | A group of computers or processors working together behind the scenes. It is often used interchangeably with parallel computing. Each processor accesses its own memory. |
| Fault tolerance | A system is fault-tolerant if it can continue performing despite parts failing. Fault tolerance helps to make your remote-boot infrastructure more robust. In the case of OS deployment servers, the whole system is fault-tolerant if the OS deployment servers back up each other. |
| For-loop | Extends from a FOR statement to an END FOR statement and executes for a specified number of iterations, defined in the FOR statement. |
| Functional programming (FP) | A style of programming that follows the mathematical function format. Declarative implies that the emphasis of the code or program is on the “what” of the solution as opposed to the “how to” of the solution. Declarative syntax abstracts out the implementation details and only emphasizes the final output, restating “the what.” We use expressions in functional programming, such as the expression f of x, as mentioned earlier. |
| Hadoop | An open-source software framework offering reliable distributed processing of large data sets by using simplified programming models. |
| Hadoop Common | Fundamental part of the Apache Hadoop framework. It refers to a collection of primary utilities and libraries that support other Hadoop modules. |
| Hadoop Distributed File System (HDFS) | A file system distributed on multiple file servers, allowing programmers to access or store files from any network or computer. It is the storage layer of Hadoop. It works by splitting the files into blocks, creating replicas of the blocks, and storing them on different machines. It is built to access streaming data seamlessly. It uses a command-line interface to interact with Hadoop. |
| HBase | A column-oriented, non-relational database system that runs on top of Hadoop Distributed File System (HDFS). It provides real-time wrangling access to the Hadoop file system. It uses hash tables to store data in indexes, allowing for random data access and making lookups faster. |
| Immutable | This type of object storage allows users to set indefinite retention on the object if they are unsure of the final duration of the retention period or want to use event-based retention. Once set to indefinite, user applications can change the object retention to a finite value. |
| Imperative programming paradigm | In this software development paradigm, functions are implicitly coded in every step used in solving a problem. Every operation is coded, specifying how the problem will be solved. This implies that pre-coded models are not called on. |
| In-memory processing | The practice of storing and manipulating data directly in a computer’s main memory (RAM), allowing for faster and more efficient data operations compared to traditional disk-based storage. |
| Iterative process | An approach to continuously improving a concept, design, or product. Creators produce a prototype, test it, tweak it, and repeat the cycle to get closer to the solution. |
| Java | A technology equipped with a programming language and a software platform. |
| Java virtual machines (JVMs) | The platform-specific component that runs a Java program. At runtime, the VM interprets the Java bytecode compiled by the Java compiler. The VM is a translator between the language and the underlying operating system and hardware. |
| JavaScript Object Notation (JSON) | A simplified data-interchange format based on a subset of the JavaScript programming language. IBM Integration Bus provides support for a JSON domain. The JSON parser and serializer process messages in the JSON domain. |
| Lambda calculus | A mathematical concept that implies every computation can be expressed as an anonymous function that is applied to a data set. |
| Lambda functions | Calculus functions, or operators. These are anonymous functions that enable functional programming. They are used to write functional programming code. |
| List processing language (Lisp) | The functional programming language that was initially used in the 1950s. Today, there are many functional programming language options, including Scala, Python, R, and Java. |
| Machine learning | A full-service cloud offering that allows developers and data scientists to collaborate and integrate predictive capabilities with their applications. |
| MapReduce | A program model and processing technique used in distributed computing based on Java. It splits the data into smaller units and processes big data. It is the first method used to query data stored in HDFS. It allows massive scalability across hundreds or thousands of servers in a Hadoop cluster. |
| Modular development | Techniques used in job designs to maximize the reuse of parallel jobs and components and save user time. |
| Parallel computing | A computing architecture in which multiple processors execute different small calculations fragmented from a large, complex problem simultaneously. |
| Parallel programming | It resembles distributed programming. It is the simultaneous use of multiple compute resources to solve a computational task. Parallel programming parses tasks into discrete parts solved concurrently using multiple processors. The processors access a shared pool of memory, which has control and coordination mechanisms in place. |
| Parallelization | Parallel regions of program code executed by multiple threads, possibly running on multiple processors. Environment variables determine the number of threads created and calls to library functions. |
| Persistent cache | Information is stored in “permanent” memory. Therefore, data is not lost after a system crash or restart, as if it were stored in cache memory. |
| Python | Easy-to-learn, high-level, interpreted, and general-purpose dynamic programming language focusing on code readability. It provides a robust framework for building fast and scalable applications for z/OS, with a rich ecosystem of modules to develop new applications like any other platform. |
| R | An open-source, optimized programming language for statistical analysis and data visualization. Developed in 1992, it has a rich ecosystem with complex data models and elegant tools for data reporting. |
| Redundancy | Duplication of data across multiple partitions or nodes in a cluster. This duplication is implemented to enhance fault tolerance and reliability. If one partition or node fails, the duplicated data on other partitions or nodes can still be used to ensure that the computation continues without interruption. Redundancy is critical in maintaining data availability and preventing data loss in distributed computing environments like Spark clusters. |
| Resilient Distributed Datasets (RDDs) | A fundamental abstraction in Apache Spark that represents distributed collections of data. RDDs allow you to perform parallel and fault-tolerant data processing across a cluster of computers. RDDs can be created from existing data in storage systems (like HDFS), and they can undergo various transformations and actions to perform operations like filtering, mapping, and aggregating. The “resilient” aspect refers to resilient distributed datasets (RDDs) ability to recover from node failures, and the “distributed” aspect highlights their distribution across multiple machines in a cluster, enabling parallel processing. |
| Scala | A general-purpose programming language that supports both object-oriented and functional programming. The most recent representative in the family of programming languages. Apache Spark is written mainly in Scala, which treats functions as first-class citizens. Functions in Scala can be passed as arguments to other functions, returned by other functions, and used as variables. |
| Scalability | The ability of a system to take advantage of additional resources, such as database servers, processors, memory, or disk space. It aims at minimizing the impact on maintenance. It is the ability to maintain all servers efficiently and quickly with minimal impact on user applications. |
| Spark applications | Include a driver program and executors that run the user’s multiple primary functions and different parallel operations in a cluster. |
| Spark Core | Often popularly referred to as “Spark.” The fault-tolerant Spark Core is the base engine for large-scale parallel and distributed data processing. It manages memory and task scheduling. It also contains the APIs used to define RDDs and other datatypes. It parallelizes a distributed collection of elements across the cluster. |
| Spark ML | Spark’s machine learning library for creating and using machine learning models on large data sets across distributed clusters. |
| Spark SQL | A Spark module for structured data processing. Users can interact with Spark SQL using SQL queries and the DataFrame API. Spark SQL supports Java, Scala, Python, and R APIs. Spark SQL uses the same execution engine to compute the result independently of the API or language used for computation. Developers can use the API to help express a given transformation. Unlike the basic Spark RDD API, Spark SQL includes a cost-based optimizer, columnar storage, and code generation to perform optimizations that equip Spark with information about the structure of data and the computation in process. |
| SQL Procedural code | A set of instructions written in a programming language within an SQL database environment. This code allows users to perform more complex tasks and create custom functions, procedures, and control structures, enabling them to manipulate and manage data in a more controlled and structured manner. |
| Streaming analytics | Help leverage streams to ingest, analyze, monitor, and correlate data from real-time data sources. They also help to view information and events as they unfold. |
| Worker node | A unit in a distributed system that performs tasks and processes data according to instructions from a central coordinator. |
Glossary 2
| Term | Definition |
|---|---|
| Aggregating data | Aggregation is a Spark SQL process frequently used to present aggregated statistics. Commonly used aggregation functions such as count(), avg(), max(), and others are built into Dataframes. Users can also perform aggregation programmatically using SQL queries and table views. |
| Analyze data using printSchema | In this phase, users examine the schema or the DataFrame column data types using the print schema method. It is imperative to note the data types in each column. Users can apply the select() function to examine data from a specific column in detail. |
| Apache Spark | An in-memory and open-source application framework for distributed data processing and iterative analysis of enormous data volumes. |
| Catalyst phases | Catalyst analyzes the query, DataFrame, unresolved logical plan, and Catalog to create a logical plan in the Analysis phase.The logical plan evolves into an optimized logical plan in the logical optimization phase. It is the rule-based optimization step of Spark SQL. Rules such as folding, pushdown, and pruning are applicable here. Catalyst generates multiple physical plans based on the logical plan in the physical planning phase. A physical plan describes computation on datasets with specific definitions explaining how to conduct the computation. A cost model then selects the physical plan with the least cost. This explains the cost-based optimization step. Code generation is the final phase. In this phase, the Catalyst applies the selected physical plan and generates Java bytecode to run on the nodes. |
| Catalyst query optimization | Catalyst Optimizer uses a tree data structure and provides the data tree rule sets in the background. Catalyst performs the following four high-level tasks to optimize a query: analysis, logical optimization, physical planning, and code generation. |
| Catalyst | Within Spark’s operational framework, it employs a pair of engines, namely Catalyst and Tungsten, in a sequential manner for query enhancement and execution. Catalyst’s primary function involves deriving an optimized physical query plan from the initial logical query plan. This optimization process entails implementing a range of transformations such as predicate pushdown, column pruning, and constant folding onto the logical plan. |
| Cost-based optimization | Cost is measured and calculated based on the time and memory that a query consumes. Catalyst optimizer selects a query path that results in minimal time and memory consumption. As queries can use multiple paths, these calculations can become quite complex when large datasets are part of the calculation. |
| Creating a view in Spark SQL | It is the first step in running SQL queries in Spark SQL. It is a temporary table used to run SQL queries. Both temporary and global temporary views are supported by Spark SQL. A temporary view has a local scope. Local scope implies that the view exists within the current Spark session on the current node. A global temporary view exists within the general Spark application. This view is shareable across different Spark sessions. |
| DAGScheduler | As Spark acts and transforms data in the task execution processes, the DAGScheduler facilitates efficiency by orchestrating the worker nodes across the cluster. This task-tracking makes fault tolerance possible, as it reapplies the recorded operations to the data from a previous state. |
| DataFrame operations | Refer to a set of actions and transformations that can be applied to a DataFrame, which is a two-dimensional data structure in Spark. Data within a DataFrame is organized in a tabular format with rows and columns, similar to a table in a relational database. These operations encompass a wide range of tasks, including reading data into a DataFrame, performing data analysis, executing data transformations (such as filtering, grouping, and aggregating), loading data from external sources, and writing data to various output formats. DataFrame operations are fundamental for working with structured data efficiently in Spark. |
| DataFrames | Data collection is categorically organized into named columns. DataFrames are conceptually equivalent to a table in a relational database and similar to a data frame in R or Python, but with greater optimizations. They are built on top of the SparkSQL RDD API. They use RDDs to perform relational queries. Also, they are highly scalable and support many data formats and storage systems. They are developer-friendly, offering integration with most big data tooling via Spark and APIs for Python, Java, Scala, and R. |
| Dataset | The newest Spark data abstraction, like RDDs and DataFrames, provide APIs to access a distributed data collection. They are a collection of strongly typed Java Virtual Machine, or JVM, objects. Strongly typed implies that datasets are typesafe, and the data set’s datatype is made explicit during its creation. They offer benefits of both RDDs, such as lambda functions, type-safety, and SQL Optimizations from SparkSQL. |
| Directed acyclic graph (DAG) | Spark uses a DAG and an associated DAGScheduler to perform RDD operations. It is a graphical structure composed of edges and vertices. Acyclic implies new edges can originate only from an existing vertex. The vertices and edges are sequential. The edges represent transformations or actions. The vertices represent RDDs. The DAGScheduler applies a graphical structure to run tasks using the RDD, performing transformation processes. DAG enables fault tolerance. Spark replicates the DAG and restores the node when a node goes down. |
| distinct ([numTasks])) | It helps in finding the number of varied elements in a dataset. It returns a new dataset containing distinct elements from the source dataset. |
| Extract, load, and transform (ELT) | It emerged because of big data processing. All the data resides in a data lake. A data lake is a pool of raw data for which the data purpose is not predefined. In a data lake, each project forms individual transformation tasks as required. It does not anticipate all the transformation requirements usage scenarios as in the case of ETL and a data warehouse. Organizations opt to use a mixture of ETL and ELT. |
| Extract, transform, load (ETL) | It is an important process in any data processing pipeline as the first step that provides data to warehouses for downstream applications, machine learning models, and other services. |
| filter (func) | It helps in filtering the elements of a data set basis its function. The filter operation is used to selectively retain elements from a data set or DataFrame based on a provided function (func). It allows you to filter and extract specific elements that meet certain criteria, making it a valuable tool for data transformation and analysis. |
| flatmap (func) | Similar to map (func) can map each input item to zero or more output items. Its function should return a Seq rather than a single item. |
| Hive tables | Spark supports reading and writing data stored in Apache Hive. |
| Java virtual machines (JVMs) | The platform-specific component that runs a Java program. At run time, the VM interprets the Java bytecode compiled by the Java Compiler. The VM is a translator between the language and the underlying operating system and hardware. |
| JavaScript Object Notation (JSON) | A simplified data-interchange format based on a subset of the JavaScript programming language. IBM® Integration Bus provides support for a JSON domain. The JSON parser and serializer process messages in the JSON domain. |
| JSON data sets | Spark infers the schema and loads the data set as a DataFrame. |
| Loading or exporting the data | In the ETL pipeline’s last step, data is exported to disk or loaded into another database. Also, users can write the data to the disk as a JSON file or save the data into another database, such as a Postgres (PostgresSQL) database. Users can also use an API to export data to a database, such as a Postgres database. |
| map (func) | It is an essential operation capable of expressing all transformations needed in data science. It passes each element of the source through a function func, thereby returning a newly formed distributed dataset. |
| Parquet | Columnar format that is supported by multiple data processing systems. Spark SQL allows reading and writing data from Parquet files, and Spark SQL preserves the data schema. |
| Python | High-level, easy-to-comprehend, interpreted, and general-purpose dynamic programming language used in code readability. It offers a robust framework that helps build quick and scalable applications for z/OS, with an ecosystem of modules to develop new applications on any platform. |
| RDD actions | It is used to evaluate a transformation in Spark. It returns a value to the driver program after running a computation. An example is the reduce action that aggregates the elements of an RDD and returns the result to the driver program. |
| RDD transformations | It helps in creating a new RDD from an existing RDD. Transformations in Spark are deemed lazy as results are not computed immediately. The results are computed after evaluation by actions. For example, map transformation passes each element of a dataset through a function. This results in a new RDD. |
| Read the data | When reading the data, users can load data directly into DataFrames or create a new Spark DataFrame from an existing DataFrame. |
| Resilient Distributed Datasets (RDDs) | A fundamental abstraction in Apache Spark that represents distributed collections of data. RDDs allow you to perform parallel and fault-tolerant data processing across a cluster of computers. RDDs can be created from existing data in storage systems (like HDFS), and they can undergo various transformations and actions to perform operations like filtering, mapping, and aggregating. The resilient aspect refers to the Resilient Distributed Datasets (RDDs) ability to recover from node failures, and the distributed aspect highlights their distribution across multiple machines in a cluster, enabling parallel processing. |
| R | An open-source optimized programming language for statistical analysis and data visualization. Developed in 1992, it has a robust ecosystem with complex data models and sophisticated tools for data reporting. |
| Scala | A programming language supporting object-oriented and functional programming. The most recent representative in the family of programming languages. Apache Spark is written mainly in Scala, which treats functions as first-class citizens. Functions in Scala can be passed as arguments to other functions, returned by other functions, and used as variables. |
| Schema | It is a collection of named objects. It provides a way to group those objects logically. A schema is also a name qualifier; it provides a way to use the same natural name for several objects and to prevent ambiguous references to those objects. |
| Spark driver program | A program that functions as software situated on the primary node of a machine. It defines operations on RDDs, specifying transformations and actions. To simplify, the Spark driver initiates a SparkContext linked to a designated Spark Master. Furthermore, it transfers RDD graphs to the Master, the location from which the standalone cluster manager operates. |
| Spark SQL memory optimization | The primary aim is to improve the run-time performance of a SQL query by minimizing the query time and memory consumption, thereby helping organizations save time and money. |
| SparkSQL | It is a Spark module that helps in structured data processing. It is used to run SQL queries on Spark DataFrames and has APIs available in Java, Scala, Python, and R. |
| SQL queries in SparkSQL | Spark SQL allows users to run SQL queries on Spark DataFrames. |
| String data type | It is the IBM® Informix® ESQL/C data type that holds character data that is null-terminated and does not contain trailing blanks. |
| Syntax error | If this error is detected while processing a control statement, the remaining statement is skipped and not processed. Any operands in the portion of the statement preceding the error are processed. |
| toDS() function | Converts data into a typed Dataset for efficient and type-safe operations in PySpark. |
| Transform the data | In this step of the ETL pipeline, users plan for required dataset transformations, if any. The transformation aims at retaining only the relevant data. Transformation techniques include data filtering, merging with other data sources, or performing columnar operations. Columnar operations include actions such as multiplying each column by a specific number or converting data from one unit to another. Transformation techniques can also be used to group or aggregate data. Many transformations are domain-specific data augmentation processes. The effort needed varies with the domain and the data. |
| Tungsten | Catalyst and Tungsten are integral components of Spark’s optimization and execution framework. Tungsten is geared towards enhancing both CPU and memory performance within Spark. Unlike Java, which was initially designed for transactional applications, it seeks to bolster these aspects by employing methods more tailored to data processing within the Java Virtual Machine (JVM). To achieve optimal CPU performance, it also adopts explicit memory management, employs cache-friendly data structures through STRIDE-based memory access, supports on-demand JVM bytecode, minimizes virtual function dispatches, and capitalizes on CPU register placement and loop unrolling. |
Glossary 3
| Term | Definition |
|---|---|
| AIOps | Implies the use of artificial intelligence to automate or enhance IT operations. It helps collect, aggregate, and work with large volumes of operations data. It also helps to identify events and patterns in large or complex infrastructure systems. It allows quick diagnosis of the root cause of issues so that users can report or fix them automatically. |
| Apache Hadoop YARN (Yet Another Resource Negotiator) | Cluster manager from the Hadoop project. It’s popular in the big data ecosystem and supports many other frameworks besides Spark. YARN clusters have their own dependencies, setup, and configuration requirements, so deploying them is more complex than Spark standalone. |
| Apache Mesos | General-purpose cluster manager with additional benefits. Using Mesos has some advantages. It can provide dynamic partitioning between Spark and other big data frameworks and scalable partitioning between multiple Spark instances. However, running Spark on Apache Mesos might require additional setup, depending on your configuration requirements. |
| Apache Spark Architecture | Consists of the driver and the executor processes. The cluster comprises the cluster manager and worker nodes. The Spark Context schedules tasks for the cluster, and the cluster manager manages the cluster’s resources. |
| Apache Spark Cluster Modes | Apache Spark offers various cluster modes for distributed computing, including standalone, YARN (Yet Another Resource Negotiator), and Apache Mesos. Each mode has specific characteristics and setup complexities. |
| Apache Spark | An open-source, distributed computing framework designed for processing large-scale data and performing data analytics. It provides libraries for various data processing tasks, including batch processing, real-time stream processing, machine learning, and graph processing. Spark is known for its speed and ease of use, making it a popular choice for big data applications. |
| Bootstrap data set (BSDS) | A Virtual Storage Access Method (VSAM) key-sequenced data set (KSDS) used to store the essential information required by IBM MQ (message queuing). The BSDS typically includes an inventory of all active and archived log data sets known to IBM MQ. IBM MQ uses this inventory to track active and archived log data sets. The BSDS plays a critical role in the proper functioning and management of IBM MQ, ensuring the integrity and availability of log data sets within the messaging system. |
| Clusters | Refer to groups of servers that are managed collectively and participate in workload management. You can have nodes within a cluster, typically individual physical computer systems with distinct host IP addresses. Each node in a cluster can run one or more application servers. Clusters are a fundamental concept in distributed computing and server management, allowing for the efficient allocation of resources and the scalability of applications and services across multiple server instances. |
| Containerization | Implies Spark applications are more portable. It makes it easier to manage dependencies and set up the required environment throughout the cluster. It also supports better resource sharing. |
| Driver program | It can be run in either client or cluster mode. In client mode, the application submitter (such as a user machine terminal) launches the driver outside the cluster. In cluster mode, the driver program is sent to and run on an available worker node inside the cluster. The driver must be able to communicate with the cluster while it is running, whether it is in client or cluster mode. |
| Dynamic configuration | Refers to a practice employed in software development to avoid hardcoding specific values directly into the application’s source code. Instead, critical configuration settings, such as the location of a master server, are stored externally and are adjustable without modifying the application’s code. |
| Environment variables | Spark application configuration method in which environment variables are loaded on each machine, so they can be adjusted on a per-machine basis if hardware or installed software differs between the cluster nodes. A common usage is to ensure each machine in the cluster uses the same Python executable by setting the “PYSPARK_PYTHON” environment variable. |
| Executor | Utilizes a set portion of local resources as memory and compute cores, running one task per available core. Each executor manages its data caching as dictated by the driver. In general, increasing executors and available cores increases the cluster’s parallelism. Tasks run in separate threads until all cores are used. When a task finishes, the executor puts the results in a new RDD partition or transfers them back to the driver. Ideally, limit utilized cores to the total cores available per node. |
| Hybrid cloud | Unifies and combines public and private cloud and on-premises infrastructure to create a single, cost-optimal, and flexible IT infrastructure. |
| IBM Analytics Engine | Works with Spark to provide a flexible, scalable analytics solution. It uses an Apache Hadoop cluster framework to separate storage and compute by storing data in object storage such as IBM Cloud Object Storage. This implies users can run compute nodes only when required. |
| IBM Spectrum Conductor | A multitenant platform for deploying and managing Spark and other frameworks on a cluster with shared resources. This enables multiple Spark applications and versions to be run together on a single large cluster. Cluster resources can be divided up dynamically, avoiding downtime. IBM Spectrum Conductor also provides Spark with enterprise-grade security. |
| IBM Watson | Creates production-ready environments for AI and machine learning by providing services, support, and holistic workflows. Reducing setup and maintenance saves time so that users can concentrate on training Spark to enhance its machine-learning capabilities. IBM Cloud Pak for Watson AIOps offers solutions with Spark that can correlate data across your operations toolchain to bring insights or identify issues in real time. |
| Java Archive (JAR) | A standard file format used to package Java classes and related resources into a single compressed file. JAR files are commonly used to bundle Java libraries, classes, and other assets into a single unit for distribution and deployment. |
| Java | Technology equipped with a programming language and a software platform. To create and develop an application using Java, users are required to download the Java Development Kit (JDK), available for Windows, macOS, and Linux. |
| Kubernetes (K8s) | A popular framework for running containerized applications on a cluster. It is an open-source system that is highly scalable and provides flexible deployments to the cluster. Spark uses a built-in native Kubernetes scheduler. It is portable, so it can be run in the same way on cloud or on-premises. |
| Local mode | Runs a Spark application as a single process locally on the machine. Executors are run as separate threads in the main process that calls “spark-submit”. Local mode does not connect to any cluster or require configuration outside a basic Spark installation. Local mode can be run on a laptop. That’s useful for testing or debugging a Spark application, for example, testing a small data subset to verify correctness before running the application on a cluster. However, being constrained by a single process means local mode is not designed for optimal performance. |
| Logging configuration | Spark application configuration method in which Spark logging is controlled by the log4j defaults file, which dictates what level of messages, such as info or errors, are logged to the file or output to the driver during application execution. |
| Properties | Spark application configuration method in which Spark properties are used to adjust and control most application behaviors, including setting properties with the driver and sharing them with the cluster. |
| Python | Easy-to-learn, high-level, interpreted, and general-purpose dynamic programming language focusing on code readability. It provides a robust framework for building fast and scalable applications for z/OS, with a rich ecosystem of modules to develop new applications the same way you would on any other platform. |
| Scala | General-purpose programming language that supports functional and object-oriented programming. The most recent representative in the family of programming languages. Apache Spark is written mainly in Scala, which treats functions as first-class citizens. Functions in Scala can be passed as arguments to other functions, returned by other functions, and used as variables. |
| Spark application | A program or set of computations written using the Apache Spark framework. It consists of a driver program and a set of worker nodes that process data in parallel. Spark applications are designed for distributed data processing, making them suitable for big data analytics and machine learning tasks. |
| Spark Cluster Manager | Communicates with a cluster to acquire resources for an application to run. It runs as a service outside the application and abstracts the cluster type. While an application is running, the Spark Context creates tasks and communicates to the cluster manager what resources are needed. Then the cluster manager reserves executor cores and memory resources. Once the resources are reserved, tasks can be transferred to the executor processes to run. |
| Spark Configuration Location | Located under the “conf” directory in the installation. By default, there are no preexisting files after installation; however, Spark provides a template for each configuration type with the filenames shown here. Users can create the appropriate file by removing the ‘.template’ extension. Inside the template files are sample configurations for standard settings. They can be enabled by uncommenting. |
| Spark Context | Communicates with the Cluster Manager. It is defined in the Driver, with one Spark Context per Spark application. |
| Spark jobs | Computations that can be executed in parallel. The Spark Context divides jobs into tasks to be executed on the cluster. |
| Spark logging | Controlled using log4j and the configuration is read through “conf/log4j-properties”. Users can adjust a log level to determine which messages (such as debug, info, or errors) are shown in the Spark logs. |
| Spark Shell environment | When Spark Shell starts, the environment automatically initializes the SparkContext and SparkSession variables. This means you can start working with data immediately. Expressions are entered in the Shell and evaluated in the driver. Entering an action on a Shell DataFrame generates Spark jobs that are sent to the cluster to be scheduled as tasks. |
| Spark Shell | Available for Scala and Python, giving you access to Spark APIs for working with data as Spark jobs. Spark Shell can be used in local or cluster mode, with all options available. |
| Spark Shuffle | Performed when a task requires other data partitions. It marks the boundary between stages. |
| Spark stages | Represents a set of tasks an executor can complete on the current data partition. Subsequent tasks in later stages must wait for that stage to be completed before beginning execution, creating a dependency from one stage to the next. |
| Spark standalone cluster | Has two main components: Workers and the master. The workers run on cluster nodes. They start an executor process with one or more reserved cores. There must be one master available which can run on any cluster node. It connects workers to the cluster and keeps track of them with heartbeat polling. However, if the master is together with a worker, do not reserve all the node’s cores and memory for the worker. |
| Spark standalone | Included with the Spark installation. It is best for setting up a simple cluster. There are no additional dependencies required to configure and deploy. Spark standalone is specifically designed to run Spark and is often the fastest way to get a cluster up and running applications. |
| Spark tasks | Tasks from a given job operate on different data subsets called partitions and can be executed in parallel. |
| Spark-submit | Spark comes with a unified interface for submitting applications called the “spark-submit” script found in the “bin/” directory. “Spark-submit” can be used for all supported cluster types and accepts many configuration options for the application or cluster. Unified interface means you can switch from running Spark in local mode to cluster by changing a single argument. “Spark-submit” works the same way, irrespective of the application language. For example, a cluster can run Python and Java applications simultaneously by passing in the required files. |
| Static configuration | Settings that are written programmatically into the application. These settings are not usually changed because they require modifying the application itself. Use static configuration for something that is unlikely to be changed or tweaked between application runs, such as the application name or other properties related to the application only. |
| Uber-JAR | An Uber-JAR is a single Java Archive (JAR) file that contains not only the application code but also all its dependencies, including transitive ones. The purpose of an Uber-JAR is to create a self-contained package that can be easily transported and executed within a computing cluster or environment. |
| Worker | Cluster node that can launch executor processes to run tasks. |
Glossary 4
| Term | Definition |
|---|---|
| Apache Spark user interface | Provides valuable insights, organized on multiple tabs, about the running application. The Jobs tab displays all jobs in the application, including job status. The Stages tab reports the state of tasks within a stage. The Storage tab shows the size of any RDDs or DataFrames that persisted to memory or disk. The Environment tab includes any environment variables and system properties for Spark or the JVM. The Executor tab displays a summary that shows memory and disk usage for any executors in use for the application. Additional tabs display based on the type of application in use. |
| Application dependency issues | Spark applications can have many dependencies, including application files such as Python script files, Java JAR files, and even required data files. Applications depend on the libraries used and their dependencies. Dependencies must be made available on all cluster nodes, either by preinstallation, including the dependencies in the Spark-submit script bundled with the application, or as additional arguments. |
| Application resource issues | CPU cores and memory can become an issue if a task is in the scheduling queue and the available workers do not have enough resources to run the tasks. As a worker finishes a task, the CPU and memory are freed, allowing the scheduling of another task. However, if the application asks for more resources that can ever become available, the tasks might never be run and eventually time out. Similarly, suppose that the executors are running long tasks that never finish. In that case, their resources never become available, which also causes future tasks to never run, resulting in a timeout error. Users can readily access these errors when they view the UI or event logs. |
| Application-id | A unique ID that Spark assigns to each application. These log files appear for each executor and driver process that the application runs. |
| Data validation | The practice of verifying the integrity, quality, and correctness of data used within Spark applications or data processing workflows. This validation process includes checking data for issues such as missing values, outliers, or data format errors. Data validation is crucial for ensuring that the data being processed in Spark applications is reliable and suitable for analysis or further processing. Various techniques and libraries, such as Apache Spark’s DataFrame API or external tools, can be employed to perform data validation tasks in Spark environments. |
| Directed acyclic graph (DAG) | Conceptual representation of a series of activities. A graph depicts the order of activities. It is visually presented as a set of circles, each representing an activity, some connected by lines, representing the flow from one activity to another. |
| Driver memory | Refers to the memory allocation designated for the driver program of a Spark application. The driver program serves as the central coordinator of tasks, managing the distribution and execution of Spark jobs across cluster nodes. It holds the application’s control flow, metadata, and the results of Spark transformations and actions. The driver memory’s capacity is a critical factor that impacts the feasibility and performance of Spark applications. It should be configured carefully to ensure efficient job execution without memory-related issues. |
| Environment tab | Entails several lists to describe the environment of the running application. These lists include the Spark configuration properties, resource profiles, properties for Hadoop, and the current system properties. |
| Executor memory | Used for processing. If caching is enabled, additional memory is used. Excessive caching results in out-of-memory errors. |
| Executors tab | A component of certain distributed computing frameworks and tools used to manage and monitor the execution of tasks within a cluster. It typically presents a summary table at the top that displays relevant metrics for active or terminated executors. These metrics may include task-related statistics, data input and output, disk utilization, and memory usage. Below the summary table, the tab lists all the individual executors that have participated in the application or job, which may include the primary driver. This list often provides links to access the standard output (stdout) and standard error (stderr) log messages associated with each executor process. The Executors tab serves as a valuable resource for administrators and operators to gain insights into the performance and behavior of cluster executors during task execution. |
| Job details | Provides information about the different stages of a specific job. The timeline displays each stage, where the user can quickly see the job’s timing and duration. Below the timeline, completed stages are displayed. In the parentheses beside the heading, users will see a quick view that displays the number of completed stages. Then, view the list of stages within the job and job metrics, including when the job was submitted, input or output sizes, the number of attempted tasks, the number of succeeded tasks, and how much data was read or written because of a shuffle. |
| Jobs tab | Commonly found in Spark user interfaces and monitoring tools, it offers an event timeline that provides key insights into the execution flow of Spark applications. This timeline includes crucial timestamps such as the initiation times of driver and executor processes, along with the creation timestamps of individual jobs within the application. The Jobs tab serves as a valuable resource for monitoring the chronological sequence of events during Spark job execution. |
| Multiple related jobs | Spark application can consist of many parallel and often related jobs, including multiple jobs resulting from multiple data sources, multiple DataFrames, and the actions applied to the DataFrames. |
| Parallelization | Parallel regions of program code executed by multiple threads, possibly running on multiple processors. Environment variables determine the number of threads created and calls to library functions. |
| Parquet | A columnar format that is supported by multiple data processing systems. Spark SQL allows reading and writing data from Parquet files, and Spark SQL preserves the data schema. |
| Serialization | Required to coordinate access to resources that are used by more than one program. An example of why resource serialization is needed occurs when one program is reading from a data set and another program needs to write to the data set. |
| Spark data persistence | Also known as caching data in Spark. Ability to store intermediate calculations for reuse. This is achieved by setting persistence in either memory or both memory and disk. Once intermediate data is computed to generate a fresh DataFrame and cached in memory, subsequent operations on the DataFrame can utilize the cached data instead of reloading it from the source and redoing previous computations. This feature is crucial for accelerating machine learning tasks that involve multiple iterations on the same data set during model training. |
| Spark History server | Web UI where the status of running and completed Spark jobs on a provisioned instance of Analytics Engine powered by Apache Spark is displayed. If users want to analyze how different stages of the Spark job are performed, they can view the details in the Spark history server UI. |
| Spark memory management | Spark memory stores the intermediate state while executing tasks such as joining or storing broadcast variables. All the cached and persisted data will be stored in this segment, specifically in the storage memory. |
| Spark RDD persistence | Optimization technique that saves the result of RDD evaluation in cache memory. Using this technique, the intermediate result can be saved for future use. It reduces the computation overhead. |
| Spark standalone | Here, the resource allocation is typically based on the number of available CPU cores. By default, a Spark application can occupy all the cores within the cluster, which might lead to resource contention if multiple applications run simultaneously. In the context of the standalone cluster manager, a ZooKeeper quorum is employed to facilitate master recovery through standby master nodes. This redundancy ensures high availability and fault tolerance in the cluster management layer. Additionally, manual recovery of the master node can be achieved using file system operations in the event of master failure, allowing system administrators to intervene and restore cluster stability when necessary. |
| SparkContext | When a Spark application is being run, as the driver program creates a SparkContext, Spark starts a web server that serves as the application user interface. Users can connect to the UI web server by entering the hostname of the driver followed by port 4040 in a browser once that application is running. The web server runs for the duration of the Spark application, so once the SparkContext stops, the server shuts down, and the application UI is no longer accessible. |
| Stages tab | Displays a list of all stages in the application, grouped by the current state of either completed, active, or pending. This example displays three completed stages. Click the Stage ID Description hyperlinks to view task details for that stage. |
| Storage tab | Displays details about RDDs that have been cached or persisted to memory and written to disk. |
| Unified memory | Unified regions in Spark shared by executor memory and storage memory. If executor memory is not used, storage can acquire all the available memory and vice versa. If the total storage memory usage falls under a certain threshold, executor memory can discard storage memory. Due to complexities in implementation, storage cannot evict executor memory. |
| User code | Made up of the driver program, which runs in the driver process, and the functions and variables serialized that the executor runs in parallel. The driver and executor processes run the application user code of an application passed to the Spark-submit script. The user code in the driver creates the SparkContext and creates jobs based on operations for the DataFrames. These DataFrame operations become serialized closures sent throughout the cluster and run on executor processes as tasks. The serialized closures contain the necessary functions, classes, and variables to run each task. |
| Workflows | Include jobs created by SparkContext in the driver program. Jobs in progress run as tasks in the executors, and completed jobs transfer results back to the driver or write to disk. |