results = spark.sql(
"SELECT * FROM people")
names = results.map(lambda p:p.name)SparkSQL
The primary goal of Spark SQL Optimization is to improve the SQL query run-time performance reducing the query’s time and memory consumption, saving organizations time and money.
- Spark SQL supports both rule-based and cost-based query optimization.
- Catalyst, also known as the Catalyst Optimizer, is the Spark SQL built-in rule-based query optimizer.
- Based on Scala functional programming constructs, Catalyst is designed to easily add new optimization techniques and features to Spark SQL.
- Developers can extend the optimizer by adding data-source-specific rules and support for new data types.
- During rule-based optimization, the SQL optimizer follows predefined rules that determine how to run the SQL query. Examples of predefined rules include validating that a table is indexed and checking that a query contains only the required columns.
- With the query itself optimized, cost-based optimization measures and calculates cost based on the time and memory that the query consumes.
- The Catalyst optimizer selects the query path that results in the lowest time and memory consumption.
- Because queries can use multiple paths, these calculations can become quite complex whenlarge datasets are part of the calculation.
- In the background, the Catalyst Optimizer uses a tree data structure and provides the data tree rule sets.
- To optimize a query, Catalyst performs the following four high-level tasks or phases:
- analysis, logical optimization, physical planning, and code generation.
Analysis
Logical Optimization
Physical Planning
Code Generation
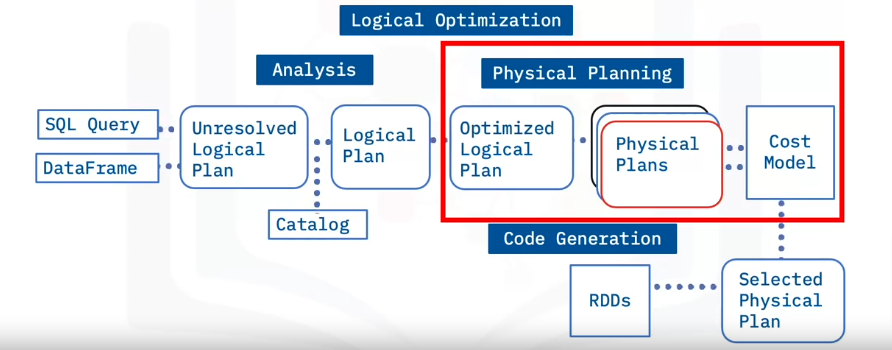
Let’s review the four Catalyst phases:
In the Analysis phase, Catalyst analyzes the query, the DataFrame, the unresolved logical plan, and the Catalog to create a logical plan.
During the Logical Optimization phase, the Logical plan evolves into an Optimized Logical Plan. This is the rule-based optimization step of Spark SQL and rules such as folding, pushdown, and pruning are applied here.
During the Physical Planning phase, Catalyst generates multiple physical plans based on the Logical Plan. A physical plan describes computation on datasets with specific definitions on how to conduct the computation. A cost model then chooses the physical plan with the least cost. This is the cost-based optimization step.
The final phase is Code Generation. Catalyst applies the selected physical plan and generates Java bytecode to run on each node.
Example
SparkSQL is a Spark module for structured data processing.
You can interact with Spark SQL using SQL queries and the DataFrame API.
Spark SQL supports Java, Scala, Python, and R APIs.
Spark SQL uses the same execution engine to compute the result independently of which API or language you are using for the computation.
Above is an example of a Spark SQL query using Python.
- The query select ALL rows from people statement is the SQL query run using Spark SQL.
- The entity “people” was registered as a table view before this command.
- Unlike the basic Spark RDD API, Spark SQL includes a cost-based optimizer, columnar storage, and code generation to perform optimizations that provide Spark with additional information about the structure of both the data and the computation in process.
Tungsten
- Tungsten optimizes the performance of underlying hardware focusing on CPU performance instead of IO. Java was initially designed for transactional applications.
- Tungsten aims to improve CPU and Memory performance by using a method more suited to data processing for the JVM to process data.
- To achieve optimal CPU performance, Tungsten applies the following capabilities:
- Tungsten manages memory explicitly and does not rely on the JVM object model or garbage collection.
- Tungsten creates cache-friendly data structures that are arranged easily and more securely using STRIDE-based memory access instead of random memory access.
- Tungsten supports JVM bytecode on-demand.
- Tungsten does not enable virtual function dispatches, reducing multiple CPU calls.
- Tungsten places intermediate data in CPU registers and enables loop unrolling.
SparkSQL - How To
Recap:
- Spark SQL Is a Spark module for structured data processing.
- Spark SQL is used to run SQL queries on Spark DataFrames and has available APIs in Java, Scala, Python, and R.
- The first step to running SQL queries in Spark SQL is to create a table view.
- A table view is a temporary table used to run SQL queries.
- Spark SQL supports both temporary and global temporary table views.
- A temporary view has local scope. Local scope means that the view exists only within the current spark session on the current node.
- A global temporary view, however, exists within the general Spark application. A global temporary view is shareable across different Spark sessions.
Create a DF from JSON
# Create a DF from json file
df = spark.read.json("people.json")Create Temp View
df.createTempView("people")SparkSQL Queries
spark.sql("SELECT *
FROM people").show()Create Global View
df.createGlobalTempView("people")
# query the table
spark.sql("SELECT *
FROM global_temp.people").show()- Note the minor syntax change, including the “Global” prefix to the function name and the “global temp” prefix to the view name.
Aggregate
- Aggregation, a standard Spark SQL process, is generally used to present grouped statistics.
- DataFrames come inbuilt with commonly used aggregation functions such as count, average, max, and others.
- You can also perform aggregation programmatically using SQL queries and table views.
Import CSV to DF
import pandas as pd
mtcars = pd.read_csv('mtcars.csv')
sdf = spark.createDataFrame(mtcars)Explore Data
sdf.select('mpg').show(5)
+----+
| mpg|
+----+
|21.0|
|21.0|
|22.8|
|21.4|
|18.7|
+----+
only showing top 5 rowsAggregate with DF Functions
{python}
car_counts = sdf.groupby(['cyl'])\
.agg({"wt": "count"})\
.sort("count(wt)", ascending=False)\
.show(5)
+---+---------+
|cyl|count(wt)|
+---+---------+
| 8| 14|
| 4| 11|
| 6| 7|
+---+---------+Aggregate with SparkSQL
# Create local view
sdf.createTempView("cars")
# Query local table
sql(" SELECT cyl, COUNT(*)
FROM cars
GROUPBY cyl
ORDER by 2 Desc")
+---+---------+
|cyl|count(wt)|
+---+---------+
| 8| 14|
| 4| 11|
| 6| 7|
+---+---------+Next, let’s look at some of the data sources that Spark SQL supports.
- Parquet is a columnar format supported by many data processing systems. Spark SQL supports reading and writing data from Parquet files, and Spark SQL preserves the data schema.
- Similarly, Spark SQL can load and write to JSON datasets by inferring the schema.
- Spark SQL also supports reading and writing data stored in Hive.