RDDs
A resilient distributed data set, also known as an RDD, is Spark’s primary data abstraction.
A resilient distributed data set, is a collection of fault tolerant elements partitioned across the cluster’s nodes capable of receiving parallel operations. Additionally, resilient distributed databases are immutable, meaning that these databases cannot be changed once created.
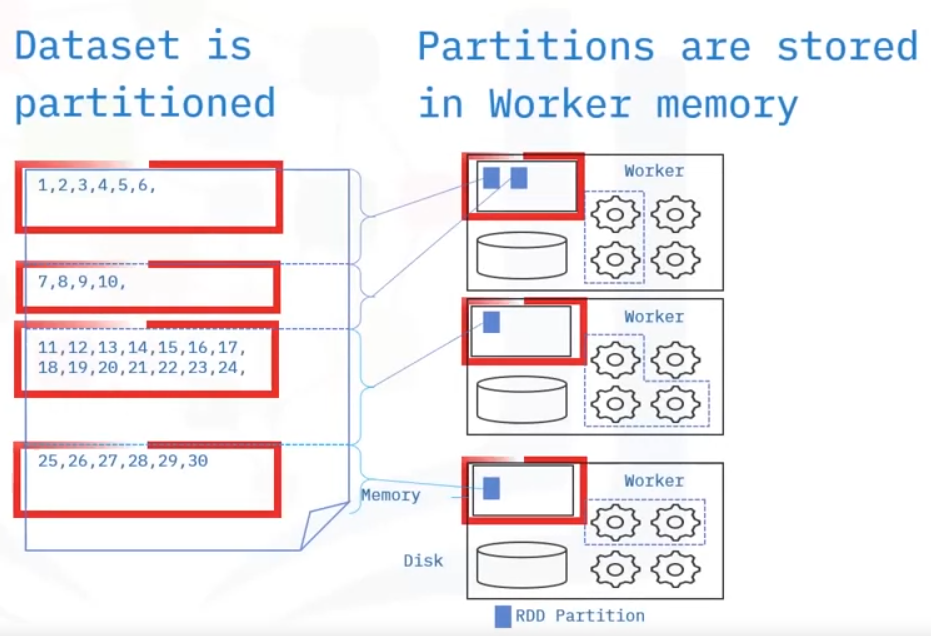
- You can create an RDD using an external or local Hadoop-supported file, from a collection, or from another RDD. RDDs are immutable and always recoverable, providing resilience in Apache Spark. RDDs can persist or cache datasets in memory across operations, which speeds up iterative operations in Spark.
- Every spark application consists of a driver program that runs the user’s main functions and runs multiple parallel operations on a cluster.
Lazy Transformation
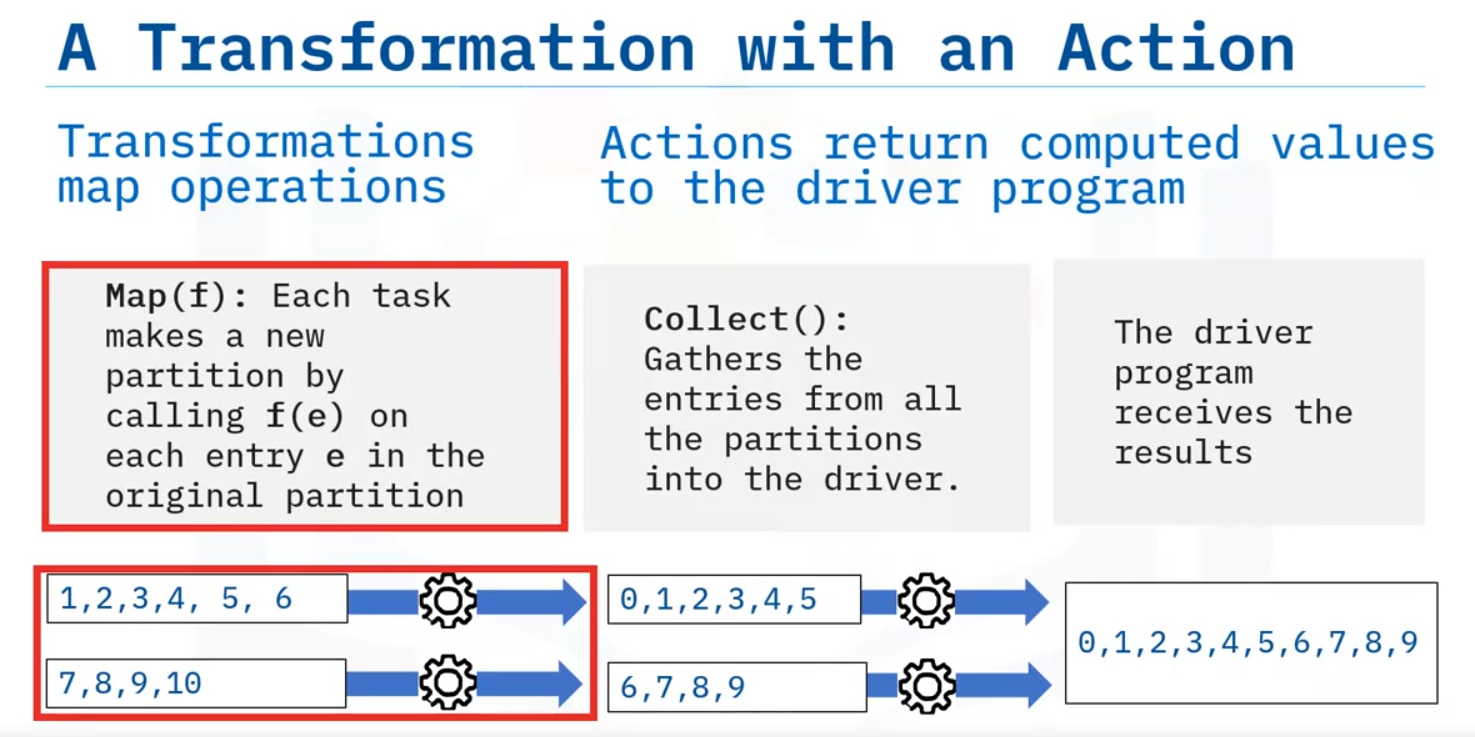
The first RDD operation to explore is a Transformation. An RDD transformation creates a new RDD from an existing RDD.
Transformations in Spark are considered lazy because Spark does not compute transformation results immediately. Instead, the results are only computed when evaluated by “actions.”
- To evaluate a transformation in Spark, you use an action. The action returns a value to the driver program after running a computation.
DAG
But how do transformations and actions happen? Spark uses a unique data structure called a Directed Acyclic Graph, knowns as a DAG, and an associated DAG Scheduler to perform RDD operations.
- Think of a DAG as a graphical structure composed of edges and vertices.
- The term “acyclic” means that new edges only originate from an existing vertex.
- In general, the vertices and edges are sequential.
- The vertices represent RDDs, and the edges represent the transformations or actions.
The DAG Scheduler applies the graphical structure to run the tasks that use the RDD to perform
transformation processes.
So, why does Spark use DAGs? DAGS help enable fault tolerance.
When a node goes down, Spark replicates the DAG and restores the node.
Let’s look at the process in more detail.
- First, Spark creates DAG when creating an RDD.
- Next, Spark enables the DAG Schedular to perform a transformation and updates the DAG.
- The DAG now points to the new RDD.
- The pointer that transforms RDD is returned to the Spark driver program.
- And, if there is an action, the driver program that calls the action evaluates the DAG only after Spark completes the action.
Transformations
map
filter
distinct
flatmap
Here are some examples of RDD transformations
| Transformation | Description |
|---|---|
| map (func) | Returns a new distributed dataset formed by passing each element of the source through a function func |
| filter(func) | Returns a new dataset formed by selecting those |
| distinct ([numTasks]) | Returns a new dataset that contains the distinct elements of the source dataset |
| flatmap (func) | Similar to map (func). Can map each input item to zero or more output items. Func should return a Seq rather than a single item |
Actions
Here are some examples of Actions:
reduce
take
collect
takeOrdered
| Action | Description |
|---|---|
| reduce (func) - aggregates dataset elements using the function func | func takes two arguments and returns one Is commutatie. Is associative. Can be computed correctly in parallel |
| take(n) | Returns an array with the first n element |
| collect() | Returns all the elements as an array - Make sure that the data will fit in driver program - AVOID this at all costs because you are pulling all the data |
| takeOrdered (n, key=func) | Returns n elements ordered in ascending order or as specified by the optional key function |